Como sabemos, ninguna prueba de hipótesis es 100 % cierta. Puesto que la prueba se basa en probabilidades, siempre existe la posibilidad de llegar a una conclusión errónea. Así, cuando se realiza una prueba de hipótesis, se pueden cometer dos tipos de error, conocidos como error de tipo I y error de tipo II. Lo que se busca es determinar cuál error tiene consecuencias más graves para tomar la decisión más apropiada.
El error de tipo I se comete cuando se rechaza la hipótesis nula, 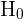 , cuando está en realidad es verdadera. Y el error de tipo II se comete cuando se acepta la hipótesis nula, , cuando ésta en realidad es falsa.
, cuando está en realidad es verdadera. Y el error de tipo II se comete cuando se acepta la hipótesis nula, , cuando ésta en realidad es falsa.
Un determinado tratamiento en fase experimental afirma tener una tasa de curación de, al menos, el 84 \% para las personas mayores de 60 años contra la diabetes. Describa los errores tipo I y tipo II en este contexto, y además, determine cuál error es más grave.
Identificamos los escenarios con los errores tipo I y II y vemos cual tiene consecuencias mas graves:
Error tipo I:
Una persona mayor de  años con diabetes cree que la tasa de curación del tratamiento es inferior al
años con diabetes cree que la tasa de curación del tratamiento es inferior al 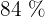 , cuando en realidad es de, al menos, el
, cuando en realidad es de, al menos, el  .
.
Error tipo II:
Un persona mayor de años con diabetes cree que el tratamiento tiene un índice de curación de, al menos, el cuando su índice de curación es inferior al .
Como podemos analizar, el error tipo II contiene la consecuencia más grave ya que, si una persona cree que el tratamiento funciona, al menos, el de las veces, lo más probable es que esto influya en la decisión de la persona sobre la conveniencia de utilizar el tratamiento como opción de curación o no.
Supongamos que la hipótesis nula,, es: El equipo de escalada de Frank es seguro. Indiquemos cuales serian el error tipo I y II.
¿Cuál tendría mayores consecuencias?
Identificamos los escenarios con los errores tipo I y II y vemos cual tiene consecuencias mas graves:
Error tipo I:
Frank piensa que su equipo de escalada puede no ser seguro cuando, en realidad, sí lo es.
Error tipo II:
Frank cree que su equipo de escalada puede ser seguro cuando, en realidad, no lo es.
Notemos que, en este caso, el error con mayores consecuencias es el tipo II, puesto que al creerse que es seguro cuando en realidad no lo es podría traer muchos accidentes.
Supongamos que la hipótesis nula, , es: La víctima de un accidente de tráfico está viva cuando llega a la sala de urgencias de un hospital.
Indiquemos cuales serian el error tipo I y II. ¿Cuál tendría consecuencias mas graves?
Identificamos los escenarios con los errores tipo I y II y vemos cual tiene consecuencias mas graves:
Error tipo I:
El equipo de emergencia cree que la víctima está muerta cuando, en realidad, está viva.
Error tipo II:
El equipo de emergencia cree que la víctima está viva cuando, en realidad, está muerta.
El error con mayores consecuencias es el error tipo I, puesto que si el equipo de emergencia cree que la víctima está muerta (cuando en realidad esta viva), no la atenderán y eso podría atraer consecuencias graves como que en verdad muera.
Unos expertos en control de calidad quieren probar la hipótesis nula de que un nuevo panel solar no es más eficaz que el modelo viejo.
¿Cuál seria un error tipo II? ¿y tipo I?
Error tipo II:
En el error tipo II aceptamos la hipótesis nula cuando en realidad esta es falsa, es decir, aceptamos que un nuevo panel solar no es más eficaz que el modelo viejo, cuando en realidad sí lo es.
Error tipo I:
En el error tipo I rechazamos la hipótesis nula cuando en realidad esta es verdadera, es decir, el nuevo panel no es mas eficaz y concluimos que sí lo es.
Los laboratorios genéticos "It’s a Boy" afirman poder aumentar la probabilidad de elegir el sexo del bebé, en ese caso, masculino. Los estadísticos quieren poner a prueba esta afirmación. Supongamos que la hipótesis nula es: Los laboratorios genéticos It’s a Boy no tienen efecto en el resultado del sexo.
Indiquemos cuales serian el error tipo I y II.
Error tipo I:
El error tipo I resulta cuando se rechaza una hipótesis nula que en realidad es verdadera. En este caso, afirmaríamos que creemos que los laboratorios genéticos It’s a Boy influyen en el resultado del sexo, cuando en realidad no tienen ningún efecto.
Error tipo II:
Este tipo de error se produce cuando no se rechaza una hipótesis nula que es falsa. En el contexto, afirmaríamos que los laboratorios genéticos It’s a Boy no influyen en el resultado del sexo de un bebé cuando, de hecho, sí lo hacen.
A la sangre donada se le hacen pruebas de enfermedades infecciosas y otros contaminantes. Como la mayoría de la sangre donada es segura, se ahorra tiempo y dinero al probar lotes de sangre donada en lugar de muestras individuales. Una cierta prueba se usa para comprobar si está presente una determinada toxina, y se desecha todo el lote si se detecta la toxina. Esto es similar a usar una hipótesis nula y una hipótesis alternativa para determinar si se debe desechar el lote. Las hipótesis que se pondrían a prueba pueden formularse como:
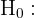 el lote no contiene la toxina.
el lote no contiene la toxina.
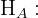 el lote contiene la toxina.
el lote contiene la toxina.
En este caso, ¿Cuál sería la consecuencia de un error de tipo I?
Recordemos que el error de tipo I se comete cuando se rechaza la hipótesis nula, , cuando está en realidad es verdadera. Es decir, es cierta, pero se rechaza.
En este caso un error tipo I seria que el lote se deseche cuando en realidad no contiene la toxina.
Un determinado fármaco experimental afirma tener una tasa de curación de, al menos, el 75 % para los hombres con cáncer de próstata. Describa los errores tipo I y tipo II en su contexto. ¿Cuál error es más grave?
Identificamos los escenarios con los errores tipo I y II y vemos cual tiene consecuencias mas graves:
Error tipo I:
Un paciente con cáncer cree que la tasa de curación del fármaco es inferior al 75 %, cuando en realidad es de, al menos, el 75 %.
Error tipo II:
Un paciente con cáncer cree que el fármaco experimental tiene un índice de curación de, al menos, el 75 % cuando su índice de curación es inferior al 75 %.
Como vemos, el error tipo II contiene la consecuencia más grave. Pues si un paciente cree que el fármaco funciona, al menos, el 75 % de las veces, lo más probable es que esto influya en la elección del paciente (y del médico) sobre la conveniencia de utilizar el fármaco como opción de tratamiento.
Supongamos que la hipótesis nula, H0, es un paciente no está enfermo. ¿Qué tipo de error tiene mayores consecuencias, el tipo I o el tipo II?
: un paciente no está enfermo.
Identificamos los escenarios con los errores tipo I y II y vemos cual tiene consecuencias mas graves:
Error tipo I:
Rechazamos la hipótesis nula, es decir, se cree que el paciente esta enfermo, cuando en realidad no lo esta.
Error tipo II:
En este caso, aceptamos la hipótesis nula cuando en realidad es falsa. Es decir, se cree que el paciente no esta enfermo, cuando en realidad lo esta.
Observemos que el error con consecuencias mas grandes seria el Tipo II, puesto que si se cree que el paciente no esta enfermo no lo atenderán cuando realmente necesita atención medica.
¿Te ha gustado este artículo? ¡Califícalo!


Apuntes es una plataforma dirigida al estudio y la práctica de las matemáticas a través de la teoría y ejercicios interactivos que ponemos a vuestra disposición. Esta información está disponible para todo aquel/aquella que quiera profundizar en el aprendizaje de esta ciencia. Será un placer ayudaros en caso de que tengáis dudas frente algún problema, sin embargo, no realizamos un ejercicio que nos presentéis de 0 sin que hayáis si quiera intentado resolverlo. Ánimo, todo esfuerzo tiene su recompensa.
El servicio de emergencia para ciertas áreas rurales de Ohio con frecuencia es un problema, especialmente durante los meses de invierno. El jefe del Departamento de Bomberos de Danville, Township está preocupado por el tiempo de respuesta a las llamadas de emergencia. Ordena una investigación para determinar si la distancia del lugar de la llamada, medida en millas, puede explicar el tiempo de respuesta, medido en minutos.Con base en 37 emergencias, se recolectaron los siguientes datos: ∑X = 234 EY = 831 ∑XY = 5,890
2X*=1.796 2r² =20,037
a. ¿Cuál es el tiempo de respuesta a una llamada que proviene de ocho millas de la estación de bomberos?. ¿Qué tan dependiente es dicha estimación, con base en el grado de dispersión de los puntos de datos alrededor de la recta de regresión?
De una población de 2,500 estudiantes de la universidad Unibe 60% Ingeniería industrial, con un nivel de confianza de 95% y un margen de error de 5%, determine la muestra?
Nota: cuando no conocemos el valor de p y q se les asigna 50% a cada uno y las cantidades que aparecen en porcentaje debe dividirse en 100.
La alcaldía de la ciudad está preocupada por el retiro masivo de las industrias hacía la capital del país, por lo usted como un importante analista en términos económicos lo debe asesorar, se seleccionó una muestra de 500 empresas de las cuales la 300 aún permanecen en la ciudad, la proporción de empresas que han salido de la ciudad se encuentra entre:
Pregunta 5Seleccione una:
a.
40 y 60%
b.
46 y 56%
c.
36 y 44 %
d.
30 y 40 %
En la siguiente tabla se presentan las cantidades promedio de jugo de frutas que empacan, en bolsas de litro, tres máquinas empacadas de una agroindustria.
-MAQUINAS
A
B
C
-PROMEDIO EMPACADO POR BOLSA
1.039 LTS
0.989 LTS
1.090 LTS
-DESVIACIÓN ESTANDAR
0.332 LTS
0.350 LTS
0.371 LTS
¿Cuál de las 3 máquinas tiene la cantidad promedio de empacado por bolsa más confiable? ¿Por qué?
ejercicio. En una ciudad de 100.000 habitantes, se quiere estimar la proporción de personas que utilizan bicicleta como medio de transporte. ¿Cuántas personas deben incluirse en la muestra para obtener un margen de error del 5% con un nivel de confianza del 95%?
10.- Las estaturas de cierta población se distribuyen N(168,8). Calcula la probabilidad de que en una muestra de 36 personas la altura media no difiera de la de la población en más de 1 cm.
28 28 28 28 24 24 20 20 20 20 20 25 25 25 27 27 27 26 22 22 22
En una escuela de 150 estudiantes se requiere realizar una investigación sobre las preferencias de las áreas de los estudiantes y se debe calcular su muestra para conocer cuántos estudiantes se le debe aplicar la encuesta, determinando que el grado de confianza es del 95%, la probabilidad de éxito de 98% y el error de calculo del 6%.
Caso de estudio: En el Perú, el Ministerio de Salud (MINSA) está interesado en conocer la prevalencia de la depresión en los adolescentes de 12 a 17 años de edad en la ciudad de Lima. Para ello, el MINSA decide realizar una encuesta a una muestra de adolescentes de esta población.
Objetivo:
El objetivo del caso de estudio es que los estudiantes apliquen la fórmula para estimar una proporción poblacional para estimar la prevalencia de la depresión en los adolescentes de 12 a 17 años de edad en la ciudad de Lima. También, debe indicar el tipo de muestreo probabilístico que deberá emplear.
¿Cuál debe ser el tamaño de muestra para estimar la prevalencia de la depresión, con un nivel de confianza del 95%, margen de error de 4%, e indica el método de selección de la muestra