









Sea  una v.a. que se distribuye normalmente, un intervalo característico es un intervalo simétrico entorno a la media
una v.a. que se distribuye normalmente, un intervalo característico es un intervalo simétrico entorno a la media  en el que la probabilidad de que un valor de la variable esté en ese intervalo es
en el que la probabilidad de que un valor de la variable esté en ese intervalo es  , es decir
, es decir

Llamamos nivel de significancia a la probabilidad que dejamos fuera del intervalo característico y lo denotamos con  . Entonces, la probabilidad que queda en el intervalo será
. Entonces, la probabilidad que queda en el intervalo será 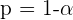 conocida como nivel de confianza el cual es representado en porcentajes en varias ocasiones.
conocida como nivel de confianza el cual es representado en porcentajes en varias ocasiones.
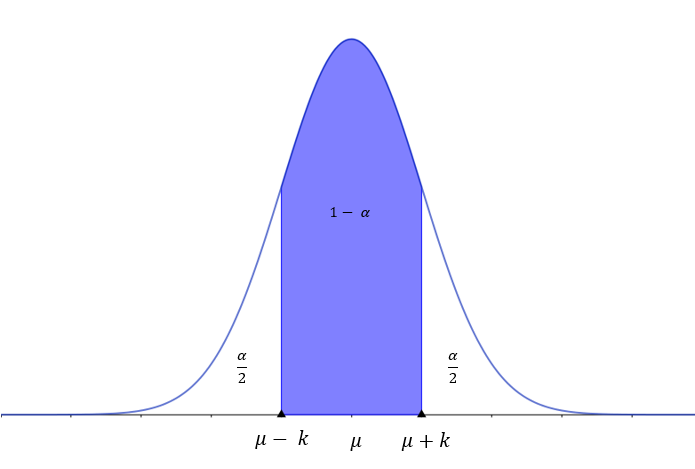
Intervalos característicos con distribución normal estándar y valor critico
Sea una distribución normal 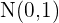 . Un intervalo característico correspondiente a una probabilidad , sería un intervalo
. Un intervalo característico correspondiente a una probabilidad , sería un intervalo 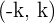 que cumpliría que la probabilidad dentro de ese intervalo sería . Es decir,
que cumpliría que la probabilidad dentro de ese intervalo sería . Es decir,

Con distribución la media es  , por tanto los intervalos característicos son de la forma .
, por tanto los intervalos característicos son de la forma .
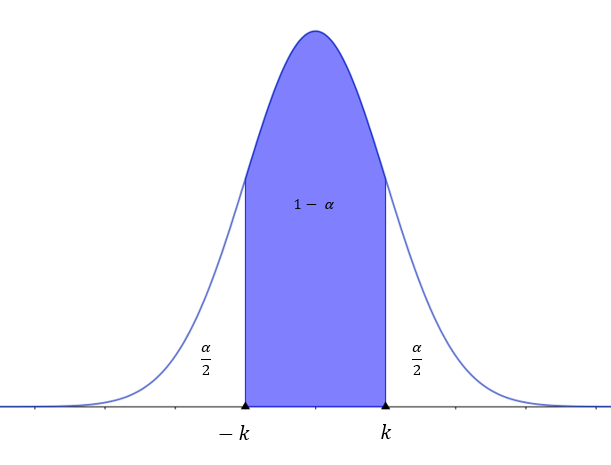
Calculemos los intervalos característicos para los valores más comunes de nivel de confianza:
Buscamos  tal que
tal que
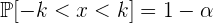
Tenemos que

entonces
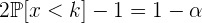
por tanto
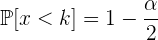 Llamemos
Llamemos 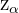 al valor de la variable que deja a su derecha una probabilidad , es decir
al valor de la variable que deja a su derecha una probabilidad , es decir 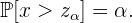
Entonces tendremos que
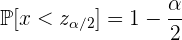
Y a 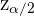 se le conoce como valor critico, cada nivel de confianza lleva asociado un valor llamado valor crítico y en una distribución normal el intervalo característico es de la forma
se le conoce como valor critico, cada nivel de confianza lleva asociado un valor llamado valor crítico y en una distribución normal el intervalo característico es de la forma 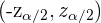 .
.
Ahora bien, si tenemos un nivel de confianza de 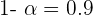 , entonces
, entonces 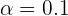 y
y 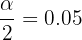 , de aquí, tenemos que hallar tal que
, de aquí, tenemos que hallar tal que
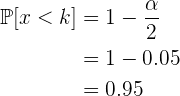
Buscando en las tablas encontramos que 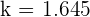 , es decir:
, es decir:
Valor critico : 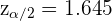
Intervalo característico : 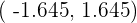
En la siguiente tabla vemos los valores críticos dado el nivel de confianza:
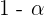 | 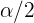 | |
|---|---|---|
| 0.90 | 0.05 | 1.645 |
| 0.95 | 0.025 | 1.96 |
| 0.99 | 0.005 | 2.575 |
En una distribución normal 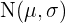 el intervalo característico correspondiente a una probabilidad
el intervalo característico correspondiente a una probabilidad  es de la forma:
es de la forma:

En la siguiente tabla vemos como quedaría el intervalo característico dado el nivel de confianza:
| | | Intervalos característicos |
|---|---|---|---|
| 0.90 | 0.05 | 1.645 | 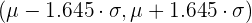 |
| 0.95 | 0.025 | 1.96 | 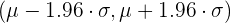 |
| 0.99 | 0.005 | 2.575 | 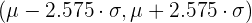 |
Resumir con IA:
¿Te ha gustado este artículo? ¡Califícalo!



Apuntes es una plataforma dirigida al estudio y la práctica de las matemáticas a través de la teoría y ejercicios interactivos que ponemos a vuestra disposición. Esta información está disponible para todo aquel/aquella que quiera profundizar en el aprendizaje de esta ciencia. Será un placer ayudaros en caso de que tengáis dudas frente algún problema, sin embargo, no realizamos un ejercicio que nos presentéis de 0 sin que hayáis si quiera intentado resolverlo. Ánimo, todo esfuerzo tiene su recompensa.
El servicio de emergencia para ciertas áreas rurales de Ohio con frecuencia es un problema, especialmente durante los meses de invierno. El jefe del Departamento de Bomberos de Danville, Township está preocupado por el tiempo de respuesta a las llamadas de emergencia. Ordena una investigación para determinar si la distancia del lugar de la llamada, medida en millas, puede explicar el tiempo de respuesta, medido en minutos.Con base en 37 emergencias, se recolectaron los siguientes datos: ∑X = 234 EY = 831 ∑XY = 5,890
2X*=1.796 2r² =20,037
a. ¿Cuál es el tiempo de respuesta a una llamada que proviene de ocho millas de la estación de bomberos?. ¿Qué tan dependiente es dicha estimación, con base en el grado de dispersión de los puntos de datos alrededor de la recta de regresión?
De una población de 2,500 estudiantes de la universidad Unibe 60% Ingeniería industrial, con un nivel de confianza de 95% y un margen de error de 5%, determine la muestra?
Nota: cuando no conocemos el valor de p y q se les asigna 50% a cada uno y las cantidades que aparecen en porcentaje debe dividirse en 100.
La alcaldía de la ciudad está preocupada por el retiro masivo de las industrias hacía la capital del país, por lo usted como un importante analista en términos económicos lo debe asesorar, se seleccionó una muestra de 500 empresas de las cuales la 300 aún permanecen en la ciudad, la proporción de empresas que han salido de la ciudad se encuentra entre:
Pregunta 5Seleccione una:
a.
40 y 60%
b.
46 y 56%
c.
36 y 44 %
d.
30 y 40 %
En la siguiente tabla se presentan las cantidades promedio de jugo de frutas que empacan, en bolsas de litro, tres máquinas empacadas de una agroindustria.
-MAQUINAS
A
B
C
-PROMEDIO EMPACADO POR BOLSA
1.039 LTS
0.989 LTS
1.090 LTS
-DESVIACIÓN ESTANDAR
0.332 LTS
0.350 LTS
0.371 LTS
¿Cuál de las 3 máquinas tiene la cantidad promedio de empacado por bolsa más confiable? ¿Por qué?
ejercicio. En una ciudad de 100.000 habitantes, se quiere estimar la proporción de personas que utilizan bicicleta como medio de transporte. ¿Cuántas personas deben incluirse en la muestra para obtener un margen de error del 5% con un nivel de confianza del 95%?
10.- Las estaturas de cierta población se distribuyen N(168,8). Calcula la probabilidad de que en una muestra de 36 personas la altura media no difiera de la de la población en más de 1 cm.
28 28 28 28 24 24 20 20 20 20 20 25 25 25 27 27 27 26 22 22 22
En una escuela de 150 estudiantes se requiere realizar una investigación sobre las preferencias de las áreas de los estudiantes y se debe calcular su muestra para conocer cuántos estudiantes se le debe aplicar la encuesta, determinando que el grado de confianza es del 95%, la probabilidad de éxito de 98% y el error de calculo del 6%.
Caso de estudio: En el Perú, el Ministerio de Salud (MINSA) está interesado en conocer la prevalencia de la depresión en los adolescentes de 12 a 17 años de edad en la ciudad de Lima. Para ello, el MINSA decide realizar una encuesta a una muestra de adolescentes de esta población.
Objetivo:
El objetivo del caso de estudio es que los estudiantes apliquen la fórmula para estimar una proporción poblacional para estimar la prevalencia de la depresión en los adolescentes de 12 a 17 años de edad en la ciudad de Lima. También, debe indicar el tipo de muestreo probabilístico que deberá emplear.
¿Cuál debe ser el tamaño de muestra para estimar la prevalencia de la depresión, con un nivel de confianza del 95%, margen de error de 4%, e indica el método de selección de la muestra